Aufgrund unserer Forenstrucktur, als Diskusionsforum, mit vielen internen Links und Querverweisen, sowie
Links auf andere Seiten oder Vidoes mag die Google Indexsierung uns nicht so wirklich, von 4.150 Post
wurden nur 1.080 Indexsiert und über 2.000 Post werden wegen den “fehlerhaften kanoischen Tags” einfach irgnoriert.
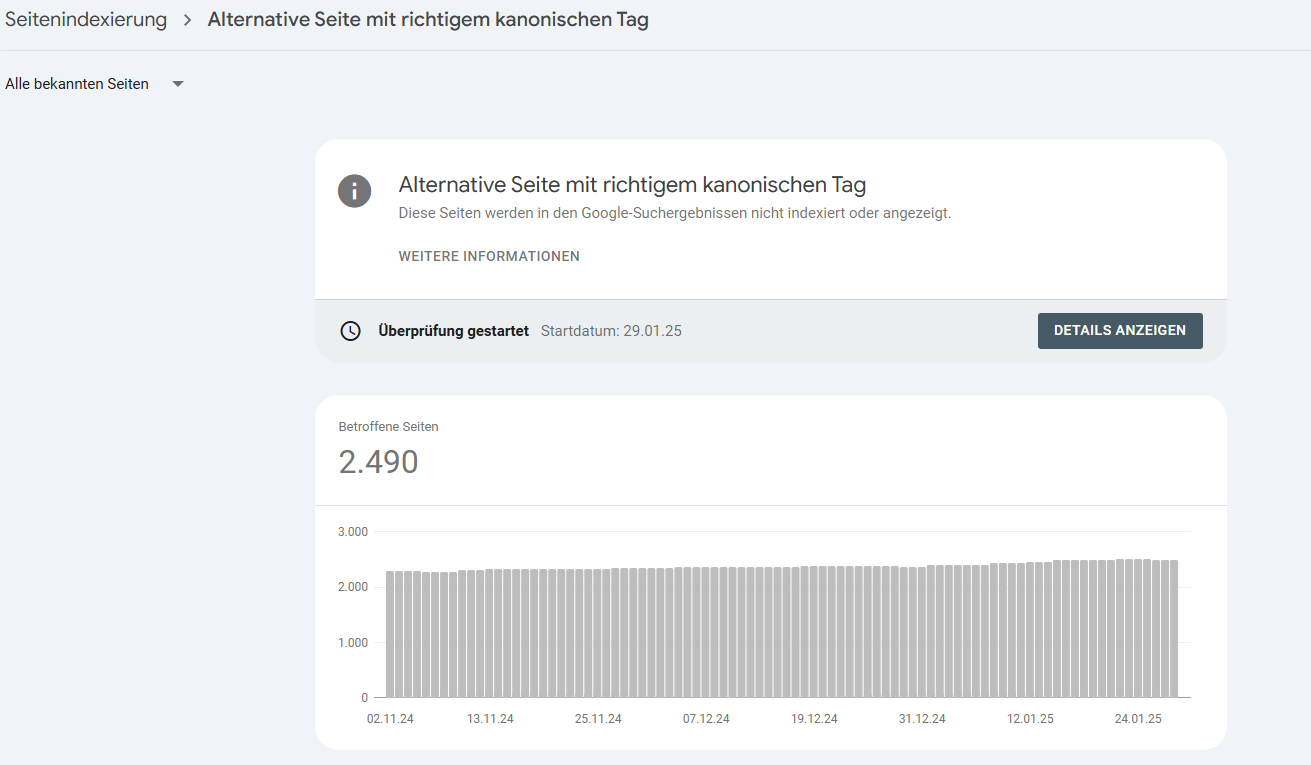
Google gibt zwar Lösungen vor, aber ich kann nicht per Hand jeden HTLM Code anpaasen, nicht für die “alten” Post und auch nicht für die neuen!
Also stellte ich Deepseek folgende Aufgabe:
Erstelle mir ein Program mit dem ich die fehlerhaften kanoischen Tags automaitsch anpassen kann
Antwort:
Um ein Programm zu erstellen, das fehlerhafte kanonische Tags automatisch anpasst, kannst du eine Skriptsprache wie Python verwenden. Das Programm wird eine HTML-Datei einlesen, nach dem <link rel=“canonical”>-Tag suchen, es bei Bedarf korrigieren und die Datei speichern. Hier ist ein einfaches Beispiel in Python:
Voraussetzungen:
Python 3.x installiert
Bibliothek BeautifulSoup für die HTML-Verarbeitung (Installation via pip install beautifulsoup4)
Python-Skript:
from bs4 import BeautifulSoup
def fix_canonical_tag(html_content, correct_url):
"""
Korrigiert den kanonischen Tag in einer HTML-Datei.
:param html_content: Der HTML-Inhalt als String
:param correct_url: Die korrekte URL für den kanonischen Tag
:return: Der korrigierte HTML-Inhalt als String
"""
soup = BeautifulSoup(html_content, 'html.parser')
# Suche nach dem vorhandenen kanonischen Tag
canonical_tag = soup.find('link', {'rel': 'canonical'})
if canonical_tag:
# Überprüfe, ob die URL korrekt ist
if canonical_tag['href'] != correct_url:
print(f"Kanonischer Tag gefunden, aber URL ist falsch: {canonical_tag['href']}")
canonical_tag['href'] = correct_url
print(f"Kanonischer Tag wurde aktualisiert: {correct_url}")
else:
print("Kanonischer Tag ist bereits korrekt.")
else:
# Füge einen neuen kanonischen Tag hinzu, falls keiner vorhanden ist
print("Kein kanonischer Tag gefunden. Ein neuer wird hinzugefügt.")
new_tag = soup.new_tag('link', rel='canonical', href=correct_url)
soup.head.append(new_tag)
return str(soup)
def process_html_file(file_path, correct_url):
"""
Verarbeitet eine HTML-Datei und korrigiert den kanonischen Tag.
:param file_path: Pfad zur HTML-Datei
:param correct_url: Die korrekte URL für den kanonischen Tag
"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
html_content = file.read()
# Korrigiere den kanonischen Tag
updated_html = fix_canonical_tag(html_content, correct_url)
# Speichere die aktualisierte HTML-Datei
with open(file_path, 'w', encoding='utf-8') as file:
file.write(updated_html)
print(f"Datei {file_path} wurde erfolgreich aktualisiert.")
except Exception as e:
print(f"Fehler beim Verarbeiten der Datei {file_path}: {e}")
# Beispielaufruf
if __name__ == "__main__":
# Pfad zur HTML-Datei und korrekte URL
html_file_path = 'beispiel.html' # Pfad zur HTML-Datei
canonical_url = 'https://www.technik22.de/korrekte-seite' # Korrekte URL
# Verarbeite die HTML-Datei
process_html_file(html_file_path, canonical_url)
Erklärung des Skripts:
BeautifulSoup: Diese Bibliothek wird verwendet, um HTML-Dateien zu parsen und zu bearbeiten.
fix_canonical_tag: Diese Funktion sucht nach einem vorhandenen kanonischen Tag. Wenn der Tag fehlerhaft ist, wird er korrigiert. Falls kein Tag vorhanden ist, wird ein neuer hinzugefügt.
process_html_file: Diese Funktion liest eine HTML-Datei ein, ruft fix_canonical_tag auf und speichert die aktualisierte Datei.
Beispielaufruf: Das Skript kann für eine einzelne Datei ausgeführt werden. Du kannst es auch erweitern, um mehrere Dateien in einem Verzeichnis zu verarbeiten.
Erweiterungen:
Batch-Verarbeitung: Du kannst das Skript erweitern, um alle HTML-Dateien in einem Verzeichnis zu durchsuchen und zu bearbeiten.
Logging: Füge ein Logging-System hinzu, um Änderungen und Fehler in einer Log-Datei zu speichern.
Kommandozeilenargumente: Mache das Skript flexibler, indem du Dateipfad und korrekte URL als Kommandozeilenargumente übergibst.
Beispiel für Batch-Verarbeitung:
import os
def process_directory(directory_path, correct_url):
"""
Verarbeitet alle HTML-Dateien in einem Verzeichnis.
:param directory_path: Pfad zum Verzeichnis
:param correct_url: Die korrekte URL für den kanonischen Tag
"""
for filename in os.listdir(directory_path):
if filename.endswith('.html'):
file_path = os.path.join(directory_path, filename)
print(f"Verarbeite Datei: {file_path}")
process_html_file(file_path, correct_url)
# Beispielaufruf für ein Verzeichnis
if __name__ == "__main__":
directory_path = 'pfad/zum/verzeichnis' # Verzeichnis mit HTML-Dateien
canonical_url = 'https://www.technik22.de/korrekte-seite' # Korrekte URL
process_directory(directory_path, canonical_url)
Mit diesem Skript kannst du fehlerhafte kanonische Tags automatisch korrigieren und deine SEO optimieren.
Okay…… jetzt habe ich die A-Karte gezogen, dachte nicht das Deepseek das so ohne weiteres macht, da ich keine Ahnung davon habe, stelle ich das hier rein und hoffe jemand kann den Code Prüfen, denn wenn das klappen könnte würde ich das auf dem Server Installieren lassen 👍️